Биномиальное распределение
Материал из MachineLearning.
Функция вероятности
| |
Функция распределения
| |
| Параметры | |
| Носитель | |
| Функция вероятности | |
| Функция распределения | |
| Математическое ожидание | |
| Медиана | одно из |
| Мода | |
| Дисперсия | |
| Коэффициент асимметрии | |
| Коэффициент эксцесса | |
| Информационная энтропия | |
| Производящая функция моментов | |
| Характеристическая функция | |
Определение
Биномиальное распределение — дискретное распределение вероятностей случайной величины принимающей целочисленные значения
с вероятностями:
Данное распределение характеризуется двумя параметрами: целым числом называемым числом испытаний, и вещественным числом
называемом вероятностью успеха в одном испытании. Биномиальное распределение — одно из основных распределений вероятностей, связанных с последовательностью независимых испытаний. Если проводится серия из
независимых испытаний, в каждом из которых может произойти "успех" с вероятностью
то случайная величина, равная числу успехов во всей серии, имеет указанное распределение. Эта величина также может быть представлена в виде суммы
независимых слагаемых, имеющих распределение Бернулли.
Основные свойства
- Математическое ожидание:
- Дисперсия:
- Асимметрия:
при
распределение симметрично относительно центра
Асимптотические приближения при больших 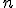
Если значения велики, то непосредственное вычисление вероятностей событий, связанных с данной случайной величиной, технически затруднительно.
В этих случаях можно использовать приближения биномиального распределения распределением Пуассона и нормальным (приближение Муавра-Лапласа).
Приближение Пуассона
Приближение распределением Пуассона применяется в ситуациях, когда значения большие, а значения
близки к нулю. При этом биномиальное распределение аппроксимируется распределением Пуассона с параметром
Строгая формулировка: если и
таким образом, что
то
Более того, справедлива следующая оценка. Пусть — случайная величина, имеющая распределение Пуассона с параметром
Тогда для произвольного множества
справедливо неравенство:
Доказательство и обзор более точных результатов, касающихся точности данного приближения, можно найти в [1, гл. III, §12].
Нормальное приближение
Приближение нормальным распределением используется в ситуациях, когда а
фиксировано. Это приближение можно рассматривать как частный случай центральной предельной теоремы, применение которой основано на представлении
в виде суммы
слагаемых. Приближение основано на том, что при указанных условиях распределение нормированной величины
где
близко к стандартному нормальному.
Локальная теорема Муавра-Лапласа
Данная теорема используется для приближенного вычисления вероятностей отдельных значений биномиального распределения. Она утверждает [1, гл. I, §6], что равномерно по всем значениям таким что
имеет место
где — плотность стандартного нормального распределения.
Интегральная теорема Муавра-Лапласа
На практике необходимость оценки вероятностей отдельных значений, которую дает локальная теорема Муавра-Лапласа, возникает нечасто. Гораздо более важно оценивать вероятности событий, включающих в себя множество значений. Для этого используется интегральная теорема, которую можно сформулировать в следующем виде [1, гл. I, §6]:
при
где случайная величина имеет стандартное нормальное распределение
и аппроксимирующая вероятность определяется по формуле
где — функция распределения стандартного нормального закона:
Есть ряд результатов, позволяющих оценить скорость сходимости. В [1, гл. I, §6] приводится следующий результат, являющийся частным случаем теоремы Берри-Эссеена:
где — функция распределения случайной величины
На практике решение о том, насколько следует доверять нормальному приближению, принимают исходя из величины
Чем она больше, тем меньше будет погрешность приближения.
Заметим, что асимптотический результат не изменится, если заменить строгие неравенства на нестрогие и наоборот. Предельная вероятность от такой замены также не поменяется, так как нормальное распределение абсолютно непрерывно и вероятность принять любое конкретное значение для него равна нулю. Однако исходная вероятность от такой замены может измениться, что вносит в формулу некоторую неоднозначность. Для больших значений изменение будет невелико, однако для небольших
это может внести дополнительную погрешность.
Для устранения этой неоднозначности, а также повышения точности приближения рекомендуется задавать интересующие события в виде интервалов с полуцелыми границами. При этом приближение получается точнее. Это связано с тем интуитивно понятным соображением, что аппроксимация кусочно-постоянной функции (функции распределения биномиального закона) с помощью непрерывной функции дает более точные приближения между точками разрыва, чем в этих точках.
Пример
Пусть
Оценим вероятность того, что число успехов будет отличаться от наиболее вероятного значения
не более чем на
. Заметим, что значение
очень мало, поэтому применение нормального приближения здесь довольно ненадежно.
Точная вероятность рассматриваемого события равна
Применим нормальное приближение с той расстановкой неравенств, которая дана выше (снизу строгое, сверху нестрогое):
Ошибка приближения равна .
Теперь построим приближение, используя интервал с концами в полуцелых точках:
Ошибка приближения равна — примерно в 5 раз меньше, чем в предыдущем подходе.
Литература
1. Ширяев А.Н. Вероятность. — М.: МЦНМО, 2004.
Ссылки
- Биномиальное распределение (Википедия)
- Binomial distribution (Wikipedia)
Интерпретация 21-го века
| Пространство элементарных событий | |
| Вероятность | |
| Максимальная вероятность
(при математическом ожидании распределения) | |
| Математическое ожидание
(как максимальное произведение математических ожиданий случайных величин) | |
| Дисперсия | |
| Максимальная дисперсия
(при математическом ожидании распределения) | |
| Ковариационная матрица | |
| Корреляционная матрица | |
|
Биномиальная схема повторных циклов случайных зависимых экспериментов
Каждый цикл экспериментов осуществляют методом выбора без возвращения в дискретной временной последовательности
Каждая из случайных величин распределения
это наступлений одного события
в - ый момент времени при условии, что в
- ый момент произошло
наступлений предшествующего события
, —
распределения Бернулли с успехом, вероятности которых
нормированы
и неизменны во время проведения экспериментов.
Если в каждом цикле экспериментов вероятность наступления события равна
, то биномиальная вероятность равна вероятности того, что при
экспериментах события
наступят
раз соответственно.
Случайная величина биномиального распределения в соответствующей точке дискретной временной последовательности имеет:
пространство элементарных событий
вероятность
математическое ожидание
и дисперсию
Пространство элементарных событий биномиального распределения есть сумма точечных пространств элементарных событий его случайных величин, образующих дискретную последовательность точек цикла, а вероятность биномиального распределения — произведение вероятностей его случайных величин.
Биномиальное распределение — совместное распределение двух случайных величин [1]
определённых на точечных пространствах элементарных событий
и принимающих в дискретные последовательные моменты времени
целые неотрицательные значения
взаимосвязанные условием
согласно которому
если в первый момент времени первая случайная величина
приняла значение
то во второй момент времени вторая случайная величина
принимает значение
Характер зависимости случайных величин в каждом цикле экспериментов:
- только первая случайная величина является независимой, а вторая случайная величина зависима от первой;
- если первая случайная величина в первый момент времени приняла своё максимально возможное значение, равное
, то вторая случайная величина во второй момент времени обязана принять своё минимальное (нулевое) значение
в противном случае не будет выполнено условие суммирования числовых значений случайных величин распределения, согласно которому
;
- если первая случайная величина в первый момент времени приняла своё минимальное (нулевое) значение
, то вторая случайная величина во второй момент времени обязана принять своё максимальное значение
в противном случае не будет выполнено условие
Характеристики случайных величин биномиального распределения:
пространство элементарных событий
вероятность
математическое ожидание
Дисперсия
производящая
и характеристическая
функции.
Характеристики биномиального распределения:
пространство элементарных событий
расположенное в точках временной последовательности,
вероятность
дисперсия
ковариационная матрица , где
корреляционная матрица , где
- квадрат критерий для полиномиально распределенных случайных величин
Урновая модель биномиального распределения содержит одну исходную урну и две приёмные урны. В начальный момент времени исходная урна содержит - множество различимых неупорядоченных элементов, а приёмные урны пусты.
Объем каждой из них не менее объёма исходной урны. Нумерация приёмных урн соответствует нумерации случайных величин биномиального распределения.
Первая выборка
в первый момент времени направляется в первую приёмную урну с вероятностью каждого элемента.
Во второй момент времени все оставшиеся элементы исходной урны, образующие вторую выборку
направляются во вторую приёмную урну с вероятностью каждого элемента.
В результате исходная урна пуста, а все её элементы размещены в приёмных урнах.
После обработки результатов разбиения множества на подмножества элементы возвращают на прежнее место, и урновая модель готова к проведению очередного цикла зависимых экспериментов.
Произведение вероятностей попадания элементов в две приёмные урны есть биномиальное распределение.
Математическое ожидание биномиального распределения
получают одним из двух способов: как максимум произведения математических ожиданий его случайных величин, или как максимум вероятности распределения.
Необходимые
и достаточные
условия получения математического ожидания биномиального распределения.
Математическое ожидание
максимальная вероятность
равна математическому ожиданию,
максимальная дисперсия
Пространство элементарных событий биномиального распределения при получении его математического ожидания
расположено в точках временной последовательности.
Урновая модель получения математического ожидания биномиального распределения содержит одну исходную урну и две приёмные урны единичных объемов. Нумерация приёмных урн соответствует нумерации случайных величин биномиального распределения.
В начальный момент времени исходная урна содержит два различимых элемента, а приёмные урны пусты.
В первый момент времени из исходной урны выбирают один элемент и направляют его в первую приёмную урну с вероятностью
.
Во второй момент времени оставшийся элемент исходной урны отправляют во вторую приёмную урну с вероятностью
.
В результате исходная урна пуста, а её два элемента по одному размещены в приёмных урнах. После обработки результатов разбиения исходного множества на два подмножества все элементы из приёмных урн возвращают в исходную урну. На этом один цикл повторных зависимых экспериментов закончен, и урновая модель готова к проведению следующего цикла экспериментов.
Произведение вероятностей попадания по одному произвольному элементу в каждую приёмную урну есть математическое ожидание биномиального распределения.
Изменение характеристик биномиального распределения в окрестности его математического ожидания приведено в таблице 2.
| Числовые значения первой случайной величины | Числовые значения второй случайной величины | Вероятность распределения | Дисперсия распределения | Математическое ожидание распределения |
| 1 | 1 | 0,50 | 0,75 | 0,50 |
| 2 | 0 | 0,25 | 0,50 | |
| 0 | 2 | 0,25 | 0,50 |
Вероятность биномиального распределения как функция двух переменных является симметричной функцией относительно своего математического ожидания.
Биномиальное распределение как процесс выполнения взаимосвязанных действий над объектами
Объекты: множество, его подмножества и их элементы как объективная реальность, существующая вне нас и независимо от нас. Биномиальное распределение это:
- случайный процесс безвозвратного разделения последовательно во времени
и в пространстве конечного
- множества различимых неупорядоченных элементов на две части
случайных объёмов, сумма которых равна объёму исходного множества:
,
- разделение множества осуществляют выборками без возвращения (изъятые из множества элементы не возвращают обратно во множество до полного окончания экспериментов),
- вероятность попадания одного произвольного элемента множества в каждое из подмножеств принимают за вероятность случайной величины распределения Бернулли с положительным исходом
,
- результаты испытаний Бернулли неизменны во время проведения разбиения множества и пронормированы
согласно аксиоматике Колмогорова,
- очерёдность следования выборок принимают за очередность следования во времени и нумерацию случайных величин
биномиального распределения,
- случайный объём каждой выборки
в момент времени
принимают за числовое значение соответствующей случайной величины
биномиального распределения,
- первая случайная величина биномиального распределения является независимой и может принимать любое случайное значение в пределах от нуля до числового значения исходного множества
,
- вторая случайная величина биномиального распределения принимает числовое значение
, равное числу элементов множества оставшееся после изъятия из него первой выборкой случайного числа элементов
,
- результаты каждого разбиения обрабатывают вероятностными методами, определяют технические характеристике всех выборок и принимают их за технические характеристики случайных величин биномиального распределения,
- минимально необходимый набор технических характеристик случайных величин и биномиального распределения в целом это: пространство элементарных событий, вероятность , математическое ожидание и дисперсия,
- математическое ожидание биномиального распределения имеет место, когда число выборок
равно числу элементов
и численно равно
.
Сравнительная оценка характеристик биномиальных распределений настоящей и традиционной интерпретаций
Цель сравнительной оценки показать, что биномиальное распределение настоящей интерпретации соответствует, а биномиальное распределение традиционной интерпретации не соответствует современным требованиям аксиоматики Колмогорова.
Несоответствие состоит в том, что, во-первых, биномиальное распределение традиционной интерпретации представлено распределением одной случайной величины, а по своей сути и определению оно должно быть распределением двух случайных величин.
Во-вторых, при неограниченном увеличении числа независимых испытаний ( ) математическое ожидание (
) биномиального распределения традиционной интерпретации устремляется к бесконечности, что недопустимо, поскольку сумма всех вероятностей распределения, включая и его математическое ожидание, в любом распределении обязана быть равной единице (см., например, таблицу 1). Кроме того, математическое ожидание (
) и дисперсия (
) первой случайной величины биномиального распределения настоящей интерпретации приняты за математическое ожидание (
) и дисперсию (
) биномиального распределения традиционной интерпретации.
Историческая справка [1]
Связь с другими распределениями
Если ,то получаем мультиномиальное распределение распределение настоящей интерпретации 21-го века.
