Критерий хи-квадрат
Материал из MachineLearning.
(→Проблемы) |
(→Проблемы) |
||
| (21 промежуточная версия не показана) | |||
| Строка 1: | Строка 1: | ||
{{TOCright}} | {{TOCright}} | ||
| + | Критерий <tex>\chi^2</tex> - статистический критерий для проверки гипотезы <tex> H_0</tex>, что наблюдаемая случайная величина подчиняется некому теоретическому закону распределения. | ||
| + | |||
== Определение == | == Определение == | ||
| - | |||
| - | |||
| - | |||
Пусть дана случайная величина X . | Пусть дана случайная величина X . | ||
'''Гипотеза <tex> H_0 </tex>''': с. в. X подчиняется закону распределения <tex>F(x)</tex>. | '''Гипотеза <tex> H_0 </tex>''': с. в. X подчиняется закону распределения <tex>F(x)</tex>. | ||
| - | |||
Для проверки гипотезы рассмотрим выборку, состоящую из n независимых наблюдений над с.в. X: | Для проверки гипотезы рассмотрим выборку, состоящую из n независимых наблюдений над с.в. X: | ||
| - | <tex>X^n = \left( x_1, \cdots | + | <tex>X^n = \left( x_1, \cdots x_n \right), \; x_i \in \left[ a, b \right], \; \forall i=1 \dots n </tex>. |
| - | По выборке построим эмпирическое распределение <tex>F^*(x)</tex> с.в X. Сравнение эмпирического <tex>F^*(x)</tex> и теоретического распределения <tex>F(x)</tex> производится с помощью специально подобранной | + | По выборке построим эмпирическое распределение <tex>F^*(x)</tex> с.в X. Сравнение эмпирического <tex>F^*(x)</tex> и теоретического распределения <tex>F(x)</tex> (предполагаемого в гипотезе) производится с помощью специально подобранной функции — [[Критерий согласия|критерия согласия]]. Рассмотрим критерий согласия Пирсона (критерий <tex>\chi^2</tex>): |
| - | + | ||
'''Гипотеза <tex> H_0^* </tex>''': Х<sup>n</sup> порождается функцией <tex>F^*(x)</tex>. | '''Гипотеза <tex> H_0^* </tex>''': Х<sup>n</sup> порождается функцией <tex>F^*(x)</tex>. | ||
| Строка 18: | Строка 15: | ||
Разделим [a,b] на k непересекающихся интервалов <tex> (a_i, b_i], \; i=1 \dots k</tex>; | Разделим [a,b] на k непересекающихся интервалов <tex> (a_i, b_i], \; i=1 \dots k</tex>; | ||
| - | Пусть <tex>n_j</tex> - количество наблюдений в j-м интервале: <tex> n_j = \sum_{i=1}^n \left[ | + | Пусть <tex>n_j</tex> - количество наблюдений в j-м интервале: <tex> n_j = \sum_{i=1}^n \left[ a_j <x_i \leq b_j \right] </tex>; |
<tex>p_j = F(b_j)-F(a_j)</tex> - вероятность попадания наблюдения в j-ый интервал при выполнении гипотезы <tex> H_0^* </tex>; | <tex>p_j = F(b_j)-F(a_j)</tex> - вероятность попадания наблюдения в j-ый интервал при выполнении гипотезы <tex> H_0^* </tex>; | ||
| - | <tex>E_j = np_j</tex> | + | <tex>E_j = np_j</tex> - ожидаемое число попаданий в j-ый интервал; |
'''Статистика:''' <tex>\chi^2 = \sum_{j=1}^k \frac{ \left( n_j-E_j \right)^2}{E_j} \sim \chi_{k-1}^2</tex> - [[Распределение хи-квадрат|Распределение хи-квадрат]] с k-1 степенью свободы. | '''Статистика:''' <tex>\chi^2 = \sum_{j=1}^k \frac{ \left( n_j-E_j \right)^2}{E_j} \sim \chi_{k-1}^2</tex> - [[Распределение хи-квадрат|Распределение хи-квадрат]] с k-1 степенью свободы. | ||
| Строка 32: | Строка 29: | ||
* <tex>\chi^2_1 < \chi^2 < \chi^2_2</tex>, гипотеза <tex>H_0</tex> выполняется. | * <tex>\chi^2_1 < \chi^2 < \chi^2_2</tex>, гипотеза <tex>H_0</tex> выполняется. | ||
| - | * <tex>\chi^2 \leq \chi^2_1</tex> (попадает в левый "хвост" распределения) гипотеза <tex>H_0</tex> | + | * <tex>\chi^2 \leq \chi^2_1</tex> (попадает в левый "хвост" распределения). Следовательно, теоретические и практические значения очень близки. Если, к примеру, происходит проверка генератора случайных чисел, который сгенерировал n чисел из отрезка [0,1] и гипотеза <tex>H_0</tex>: выборка <tex>X^n</tex> распределена равномерно на [0,1], тогда генератор нельзя называть случайным (гипотеза случайности не выполняется), т.к. выборка распределена слишком равномерно, но гипотеза <tex>H_0</tex> выполняется. |
* <tex>\chi^2 \geq \chi^2_2</tex> (попадает в правый "хвост" распределения) гипотеза <tex>H_0</tex> отвергается. | * <tex>\chi^2 \geq \chi^2_2</tex> (попадает в правый "хвост" распределения) гипотеза <tex>H_0</tex> отвергается. | ||
| Строка 38: | Строка 35: | ||
== Пример 1 == | == Пример 1 == | ||
| - | Проверим гипотезу <tex>H_0</tex>: если взять случайную выборку 100 человек из | + | Проверим гипотезу <tex>H_0</tex>: если взять случайную выборку 100 человек из всего [http://ru.wikipedia.org/wiki/%D0%9D%D0%B0%D1%81%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D0%B5_%D0%9A%D0%B8%D0%BF%D1%80%D0%B0 населения острова Кипр] (генеральной совокупности), где количество мужчин и женщин примерно одинаково (встречаются с одинаковой частотой), то в наблюдаемой выборке отношение количества мужчин и женщин будет соотноситься с частотой как и во всей генеральной выборке(50/50). Пусть в наблюдаемой выборке 46 мужчин и 54 женщины, тогда число степеней свобод <tex>k-1=2-1=1</tex> и |
<tex>\chi^2 = \sum_{j=1}^k \frac{ \left( n_j-E_j \right)^2}{E_j}= \frac{\left(46-50 \right)^2}{50}+\frac{\left(54-50 \right)^2}{50}=0,64 </tex> | <tex>\chi^2 = \sum_{j=1}^k \frac{ \left( n_j-E_j \right)^2}{E_j}= \frac{\left(46-50 \right)^2}{50}+\frac{\left(54-50 \right)^2}{50}=0,64 </tex> | ||
| - | Т.о. при уровне значимости <tex>\alpha=0.05</tex> | + | Т.о. при уровне значимости <tex>\alpha=0.05</tex> о выполнении гипотезы <tex>H_0</tex> ничего сказать нельзя |
| + | т.к. значение <tex>\chi^2</tex>> <tex>\chi_{0.05,1}^2</tex> (см. [http://ru.wikipedia.org/wiki/Квантили_распределения_хи-квадрат Таблицу распределения <tex>\chi^2_1</tex>]). | ||
== Сложная гипотеза == | == Сложная гипотеза == | ||
| - | Гипотеза <tex>H_0^*</tex>: Х<sup>n</sup> порождается функцией <tex>F(x,\theta),\; \theta \in R^d,\; \theta</tex> - | + | Гипотеза <tex>H_0^*</tex>: Х<sup>n</sup> порождается функцией <tex>F(x,\theta),\; \theta \in R^d,\; \theta</tex> - неизвестный параметр. Найдем приближенное значение параметра <tex>\hat{\theta}</tex> с помощью [[Метод максимального правдоподобия|метода максимального правдоподобия]], основанного на частотах (фиксируем интервалы <tex>\left(a_j,b_j \right]</tex> для <tex>j=1 \dots k</tex>). |
| - | + | <tex> n_j = \sum_{i=1}^n \left[ a_j <x_i \leq b_j \right] </tex> - число попаданий значений элементов выборки в j-ый интервал. | |
| + | |||
| + | <tex>p_j(\theta)=F(b_j,\theta)-F(a_j,\theta)</tex>, | ||
<tex>\hat{\theta} = \arg \max_{\theta} \sum n_j \ln p_j(\theta) </tex> | <tex>\hat{\theta} = \arg \max_{\theta} \sum n_j \ln p_j(\theta) </tex> | ||
| Строка 58: | Строка 58: | ||
== Пример 2 == | == Пример 2 == | ||
| + | '''Задача о бомбардировках Лондона [Лагутин, Т2].''' | ||
| + | Задача возникла в связи с бомбардировками Лондона во время Второй мировой войны. Для улучшения организации оборонительных мероприятий, необходимо было понять цель противника. Для этого территорию города условно разделили сеткой из 24-ёх горизонтальных и 24-ёх вертикальных линий на 576 равных участков. В течении некторого времени в центре организации обороны города собиралась информация о количестве попаданий снарядов в каждый из участков. В итоге были получены следующие данные: | ||
| - | + | {| border=1 cellpadding="6" cellspacing="0" | |
| + | |- align="center" | ||
| + | ! Число попаданий | ||
| + | |0 || 1 || 2 || 3 || 4 || 5 || 6 || 7 | ||
| + | |- align="center" | ||
| + | ! Количество участков | ||
| + | |229 || 211 || 93 || 35 || 7 || 0 || 0 || 1 | ||
| + | |} | ||
| + | |||
| + | Гипотеза <tex>H_0</tex>: стрельба случайна (нет "целевых" участков). | ||
Закон редких событий ([[Распределение Пуассона|распределение Пуассона]]) | Закон редких событий ([[Распределение Пуассона|распределение Пуассона]]) | ||
| - | <tex>P{S=j}=\frac{\lambda^j}{j!}e^{-\lambda}</tex>, S - число попаданий <tex>\hat{\lambda}=0.924</tex> | + | <tex>P\{S=j\}=\frac{\lambda^j}{j!}e^{-\lambda}</tex>, где S - число попаданий, <tex>\hat{\lambda}=0.924</tex>. |
<tex>\chi^2 = \sum_{j=1}^k \frac{ \left( n_j-E_j \right)^2}{E_j}= 32.6 \sim \chi_{8-1-1}^2</tex> | <tex>\chi^2 = \sum_{j=1}^k \frac{ \left( n_j-E_j \right)^2}{E_j}= 32.6 \sim \chi_{8-1-1}^2</tex> | ||
| - | Тогда при уровне значимости <tex>\alpha=0.05</tex> гипотеза <tex>H_0</tex> не выполняется (см. таблицу значений ф-ии <tex>\chi^2_6</tex>). | + | Тогда при уровне значимости <tex>\alpha=0.05</tex> гипотеза <tex>H_0</tex> не выполняется (см. [http://www.statsoft.ru/home/textbook/modules/sttable.html таблицу значений ф-ии <tex>\chi^2_6</tex>]). |
Объединим события (4,5,6,7) с малой частотой попаданий в одно, тогда имеем: | Объединим события (4,5,6,7) с малой частотой попаданий в одно, тогда имеем: | ||
| - | 1 | + | {| border=1 cellpadding="6" cellspacing="0" |
| + | |- align="center" | ||
| + | ! Число попаданий | ||
| + | |0 || 1 || 2 || 3 || 4-7 | ||
| + | |- align="center" | ||
| + | ! Количество участков | ||
| + | |229 || 211 || 93 || 35 || 8 | ||
| + | |} | ||
| - | <tex>\chi^2 = 1.05 \sim \chi_{5-1-1}^2</tex> | + | <tex>\chi^2 = 1.05 \sim \chi_{5-1-1}^2</tex>, тогда при <tex>\alpha=0.05</tex> гипотеза <tex>H_0</tex> верна. |
| - | + | ||
| - | + | ||
== Проблемы == | == Проблемы == | ||
Критерий <tex>\chi^2</tex> ошибается на выборках с низкочастотными (редкими) событиями. Решить эту проблему можно отбросив низкочастотные события, либо объединив их с другими событиями. Этот способ называется коррекцией Йетса (Yates' correction). | Критерий <tex>\chi^2</tex> ошибается на выборках с низкочастотными (редкими) событиями. Решить эту проблему можно отбросив низкочастотные события, либо объединив их с другими событиями. Этот способ называется коррекцией Йетса (Yates' correction). | ||
| + | |||
| + | == Дополнения == | ||
| + | Эта статья не отражает всех нюансов применения критериев согласия типа <tex>\chi^2</tex>. Для корректного применения критерия целесообразно ознакомиться со следующими источниками: | ||
| + | * [http://ami.nstu.ru/~headrd/seminar/xi_square/start1.htm Р 50.1.033–2001. Рекомендации по стандартизации. Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Часть I. Критерии типа хи-квадрат. – М.: Изд-во стандартов. 2002. – 87 с.] | ||
| + | * [http://ami.nstu.ru/~headrd/seminar/publik_html/mr_x2_1998.pdf Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Методические рекомендации. Часть I. Критерии типа <tex>\chi^2</tex>. – Новосибирск: Изд-во НГТУ, 1998. – 126 c.] | ||
| + | * [http://ami.nstu.ru/~headrd/seminar/publik_html/Statistical_Data_Analysis.pdf Статистический анализ данных, моделирование и исследование вероятностных закономерностей. Компьютерный подход : монография. – Новосибирск : Изд-во НГТУ, 2011. – 888 с. (главы 2 и 4)] | ||
== Литература == | == Литература == | ||
| + | ''Лапач С. Н. , Чубенко А. В., Бабич П. Н.'' Статистика в науке и бизнесе. (стр. 204,316) — Киев: Морион, 2002. | ||
| + | |||
| + | ''Лагутин М. Б.'' Наглядная математическая статистика. (Том 2, стр. 174) — М.: П-центр, 2003. | ||
| + | |||
| + | ''Кулаичев А. П.'' Методы и средства комплексного анализа данных. (стр. 162) — М.: Форум–Инфра-М, 2006. | ||
| + | |||
== Ссылки == | == Ссылки == | ||
| - | [[http://en.wikipedia.org/wiki/Pearson%27s_chi-square_test Критерий хи-квадрат (en.wiki)]] | + | * [[http://en.wikipedia.org/wiki/Pearson%27s_chi-square_test Критерий хи-квадрат (en.wiki)]] |
| + | * [http://ru.wikipedia.org/wiki/%D0%9A%D0%B2%D0%B0%D0%BD%D1%82%D0%B8%D0%BB%D0%B8_%D1%80%D0%B0%D1%81%D0%BF%D1%80%D0%B5%D0%B4%D0%B5%D0%BB%D0%B5%D0%BD%D0%B8%D1%8F_%D1%85%D0%B8-%D0%BA%D0%B2%D0%B0%D0%B4%D1%80%D0%B0%D1%82 Квантили распределения хи-квадрат] | ||
{{stub}} | {{stub}} | ||
[[Категория:Прикладная статистика]] | [[Категория:Прикладная статистика]] | ||
| + | [[Категория:Статистические тесты]] | ||
[[Категория:Энциклопедия анализа данных]] | [[Категория:Энциклопедия анализа данных]] | ||
Текущая версия
|
Критерий - статистический критерий для проверки гипотезы
, что наблюдаемая случайная величина подчиняется некому теоретическому закону распределения.
Определение
Пусть дана случайная величина X .
Гипотеза : с. в. X подчиняется закону распределения
.
Для проверки гипотезы рассмотрим выборку, состоящую из n независимых наблюдений над с.в. X:
.
По выборке построим эмпирическое распределение
с.в X. Сравнение эмпирического
и теоретического распределения
(предполагаемого в гипотезе) производится с помощью специально подобранной функции — критерия согласия. Рассмотрим критерий согласия Пирсона (критерий
):
Гипотеза : Хn порождается функцией
.
Разделим [a,b] на k непересекающихся интервалов ;
Пусть - количество наблюдений в j-м интервале:
;
- вероятность попадания наблюдения в j-ый интервал при выполнении гипотезы
;
- ожидаемое число попаданий в j-ый интервал;
Статистика: - Распределение хи-квадрат с k-1 степенью свободы.
Проверка гипотезы 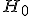

В зависимости от значения критерия , гипотеза
может приниматься, либо отвергаться:
-
, гипотеза
-
(попадает в левый "хвост" распределения). Следовательно, теоретические и практические значения очень близки. Если, к примеру, происходит проверка генератора случайных чисел, который сгенерировал n чисел из отрезка [0,1] и гипотеза
распределена равномерно на [0,1], тогда генератор нельзя называть случайным (гипотеза случайности не выполняется), т.к. выборка распределена слишком равномерно, но гипотеза
-
(попадает в правый "хвост" распределения) гипотеза
Пример 1
Проверим гипотезу : если взять случайную выборку 100 человек из всего населения острова Кипр (генеральной совокупности), где количество мужчин и женщин примерно одинаково (встречаются с одинаковой частотой), то в наблюдаемой выборке отношение количества мужчин и женщин будет соотноситься с частотой как и во всей генеральной выборке(50/50). Пусть в наблюдаемой выборке 46 мужчин и 54 женщины, тогда число степеней свобод
и
Т.о. при уровне значимости о выполнении гипотезы
ничего сказать нельзя
т.к. значение
>
(см. Таблицу распределения
).
Сложная гипотеза
Гипотеза : Хn порождается функцией
- неизвестный параметр. Найдем приближенное значение параметра
с помощью метода максимального правдоподобия, основанного на частотах (фиксируем интервалы
для
).
- число попаданий значений элементов выборки в j-ый интервал.
,
Теорема Фишера Для проверки сложной гипотезы критерий представляется в виде:
, где
Пример 2
Задача о бомбардировках Лондона [Лагутин, Т2]. Задача возникла в связи с бомбардировками Лондона во время Второй мировой войны. Для улучшения организации оборонительных мероприятий, необходимо было понять цель противника. Для этого территорию города условно разделили сеткой из 24-ёх горизонтальных и 24-ёх вертикальных линий на 576 равных участков. В течении некторого времени в центре организации обороны города собиралась информация о количестве попаданий снарядов в каждый из участков. В итоге были получены следующие данные:
| Число попаданий | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 |
|---|---|---|---|---|---|---|---|---|
| Количество участков | 229 | 211 | 93 | 35 | 7 | 0 | 0 | 1 |
Гипотеза : стрельба случайна (нет "целевых" участков).
Закон редких событий (распределение Пуассона)
, где S - число попаданий,
.
Тогда при уровне значимости гипотеза
не выполняется (см. таблицу значений ф-ии
).
Объединим события (4,5,6,7) с малой частотой попаданий в одно, тогда имеем:
| Число попаданий | 0 | 1 | 2 | 3 | 4-7 |
|---|---|---|---|---|---|
| Количество участков | 229 | 211 | 93 | 35 | 8 |
, тогда при
гипотеза
верна.
Проблемы
Критерий ошибается на выборках с низкочастотными (редкими) событиями. Решить эту проблему можно отбросив низкочастотные события, либо объединив их с другими событиями. Этот способ называется коррекцией Йетса (Yates' correction).
Дополнения
Эта статья не отражает всех нюансов применения критериев согласия типа . Для корректного применения критерия целесообразно ознакомиться со следующими источниками:
- Р 50.1.033–2001. Рекомендации по стандартизации. Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Часть I. Критерии типа хи-квадрат. – М.: Изд-во стандартов. 2002. – 87 с.
- Прикладная статистика. Правила проверки согласия опытного распределения с теоретическим. Методические рекомендации. Часть I. Критерии типа
. – Новосибирск: Изд-во НГТУ, 1998. – 126 c.
- Статистический анализ данных, моделирование и исследование вероятностных закономерностей. Компьютерный подход : монография. – Новосибирск : Изд-во НГТУ, 2011. – 888 с. (главы 2 и 4)
Литература
Лапач С. Н. , Чубенко А. В., Бабич П. Н. Статистика в науке и бизнесе. (стр. 204,316) — Киев: Морион, 2002.
Лагутин М. Б. Наглядная математическая статистика. (Том 2, стр. 174) — М.: П-центр, 2003.
Кулаичев А. П. Методы и средства комплексного анализа данных. (стр. 162) — М.: Форум–Инфра-М, 2006.
