Алгоритм LOWESS
Материал из MachineLearning.
(→Алгоритм) |
(→Выбор ядра \bar{K}) |
||
| Строка 73: | Строка 73: | ||
=== Выбор ядра <tex>\bar{K} </tex>=== | === Выбор ядра <tex>\bar{K} </tex>=== | ||
| + | |||
| + | В качестве ядра <tex>\bar{K} </tex> большинство практических источников рекомендуют | ||
| + | использовать следующее: | ||
| + | Пусть <tex>s </tex> - есть медиана для оценок <tex>\gamma_1,\ldots,\gamma_m</tex>, | ||
| + | тогда <tex>\gamma_i = B(\frac{\varepsilon_i}{6s})</tex>, где <tex>B=(1-|z|)^2, |z|<1 </tex> и 0 иначе. | ||
==Литература== | ==Литература== | ||
Версия 12:51, 31 декабря 2009
| | Статья плохо доработана. Имеются указания по её улучшению: |

Алгоритм LOWESS (locally weighted scatter plot smoothing) - локально взвешенное сглаживание.
Содержание |
Постановка задачи
Решается задача восстановления регрессии. Задано пространство объектов и множество возможных
ответов
. Существует неизвестная целевая зависимость
,
значения которой известны только на объектах обучающей выборки
.
Требуется построить алгоритм
, аппроксимирующий целевую зависимость
.
Непараметрическая регрессия
Непараметрическое восстановление регрессии основано на идее, что значение вычисляется
для каждого объекта
по нескольким ближайшим к нему объектам обучающей выборки.
В формуле Надарая–Ватсона для учета близости объектов обучающей выборки к объекту
предлагалось использовать невозрастающую, гладкую, ограниченную функцию
, называемую ядром:
Параметр называется шириной ядра или шириной окна сглаживания. Чем меньше
,
тем быстрее будут убывать веса
по мере удаления
от
.
В общем случае
зависит от объекта
, т.е.
. Тогда веса вычисляются по формуле
Оптимизация ширины окна
Чтобы оценить при данном и
точность локальной аппроксимации в точке
,
саму эту точку необходимо исключить из обучающей выборки. Если этого не делать, минимум ошибки будет
достигаться при
. Такой способ оценивания оптимальной ширины окна называется скользящим контролем
с исключением объектов по одному (leave-one-out, LOO):
Проблема выбросов
Оценка Надарайя–Ватсона
крайне чувствительна к большим одиночным выбросам. На практике легко идентифицируются только грубые ошибки,
возникающие, например, в результате сбоя оборудования или невнимательности персонала при подготовке данных.
В общем случае можно лишь утверждать, что чем больше величина ошибки
тем в большей степени прецедент является выбросом , и тем меньше должен быть его вес.
Эти соображения приводят к идее домножить веса
на коэффициенты
, где
— ещё одно ядро, вообще говоря,
отличное от
.
Алгоритм LOWESS
Вход
- обучающая выборка;
весовые функции;
Выход
Коэффициенты
Алгоритм
- 1: инициализация
- 2: повторять
- 3: вычислить оценки скользящего контроля на каждом объекте:
- 4: вычислить новые значения коэффициентов
:
;
- 5: пока коэффициенты
Коэффициенты , как и ошибки
, зависят от функции
, которая,
в свою очередь, зависит от
. На каждой итерации строится функция
,
затем уточняются весовые множители
. Как правило, этот процесс сходится довольно быстро.
Он называется локально взвешенным сглаживанием (locally weighted scatter plot smoothing, LOWESS).
Выбор ядра 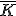
В качестве ядра большинство практических источников рекомендуют
использовать следующее:
Пусть
- есть медиана для оценок
,
тогда
, где
и 0 иначе.
Литература
- Воронцов К.В. Лекции по алгоритмам восстановления регрессии. — 2007.
- A.I. McLeod Statistics 259b Robust Loess: S lowess.
См. также
- Непараметрическая регрессия
- Регрессионный анализ
- Local regression
- Расин, Джеффри (2008) «Непараметрическая эконометрика: вводный курс», Квантиль, №4, стр. 7–56.
| | Данная статья является непроверенным учебным заданием.
До указанного срока статья не должна редактироваться другими участниками проекта MachineLearning.ru. По его окончании любой участник вправе исправить данную статью по своему усмотрению и удалить данное предупреждение, выводимое с помощью шаблона {{Задание}}. См. также методические указания по использованию Ресурса MachineLearning.ru в учебном процессе. |
→
